
Criando Coleções no Python: Implemente 2 Métodos e Ganhe 10
Nesse vídeo, mostro como implementar uma Sequence[T] no Python para que ela funcione exatamente como uma list imutável.

Fala seus Nerds, para inaugurar este espaço, quero mergulhar com você em um dos aspectos mais elegantes e poderosos do design da linguagem Python: o seu Data Model.
Você já parou para pensar na "mágica" por trás de uma simples lista? Como ela sabe o que fazer quando você pede um fatiamento como minha_lista[1:5], usa ela em um loop for, ou checa se um item está contido nela com o operador in?
A resposta não é mágica, é um design genial baseado em protocolos e contratos. E a melhor parte é que o Python não guarda esse poder apenas para os seus tipos nativos. Qualquer um de nós pode criar nossas próprias classes que se comportam exatamente como uma list ou tuple.
É o que exploramos na Aula 6 do nosso curso de Type Hints gratuito.
Sequence[T]
No coração dessa funcionalidade está o collections.abc (Abstract Base Classes), um conjunto de classes abstratas e protocolos para os diversos tipos de coleções. A mãe direta das tuplas é a Sequence.
O contrato de uma Sequence é surpreendentemente simples. Para que um objeto seja considerado uma sequência ordenada, ele só precisa saber fazer duas coisas:
Informar seu tamanho (
__len__).Fornecer um item quando pedimos por um índice (
__getitem__).
É isso. Se você ensinar sua classe a fazer apenas isso, o Python, por baixo dos panos, te dá todo o resto de presente.
Um exemplo de implementação
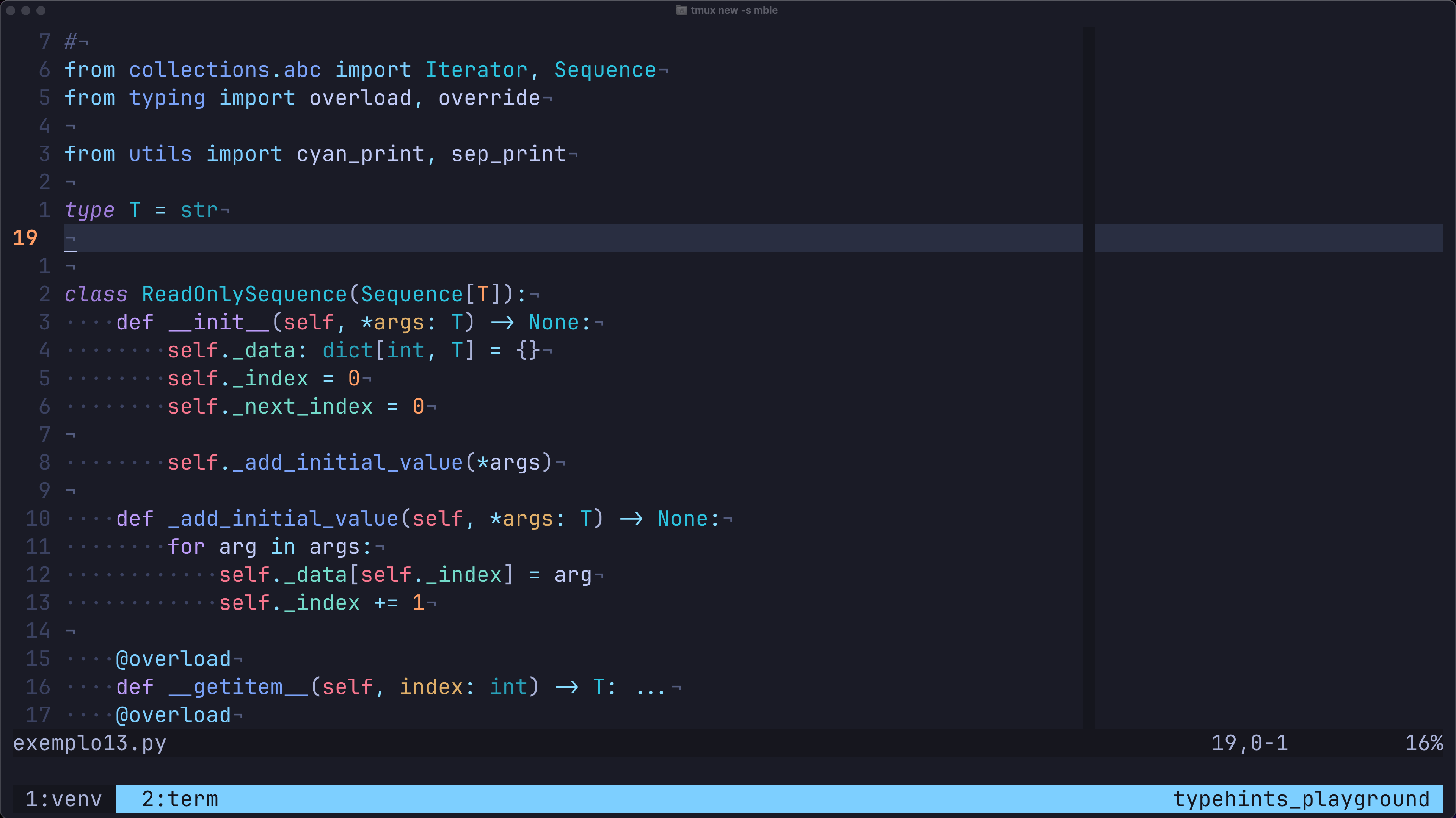
No último vídeo do nosso curso gratuito, criamos uma classe ReadOnlySequence do zero. A estrutura inicial é simples assim:
from collections.abc import Sequence
from typing import TypeVar
T = TypeVar("T")
class ReadOnlySequence(Sequence[T]):
def __init__(self, *data: T) -> None:
self._data = list(data)
def __len__(self) -> int:
return len(self._data)
def __getitem__(self, index: int | slice):
# ... aqui está parte da mágica ...
return self._data[index]Ao implementar esses dois "dunder methods" (__len__ e __getitem__), nossa classe automaticamente ganha os seguintes superpoderes, sem escrevermos mais nenhuma linha de código para eles:
Iteração: Funciona perfeitamente em loops
for.Fatiamento (Slicing): Aceita sintaxes como
minha_sequencia[5:10].Verificação de Pertença: O operador
in(if item in minha_sequencia:) funciona.Funções Nativas:
reversed(),index(), ecount()passam a funcionar.
Essa é a beleza do Data Model do Python: você implementa um contrato pequeno e ganha uma integração imensa com a linguagem.
Da Teoria para a Prática
Claro que existem detalhes importantes no caminho. Como exatamente implementamos o __getitem__ para que ele entenda a diferença entre um índice inteiro e uma fatia? Como usamos o decorador @overload para garantir que a tipagem estática disso seja perfeita? E como podemos até mesmo transformar nossa classe em seu próprio iterador para otimizar os loops?
É aí que a aula em vídeo entra. Nela, eu te guio passo a passo por toda a implementação, mostrando cada detalhe, cada "pegadinha" e cada decisão de design.
Se você ficou curioso para ver essa mágica acontecendo e quer aprender a construir seus próprios tipos de dados robustos, a aula completa está te esperando.
Assista à Aula 6 completa no YouTube e desvende o poder dos ABCs:
Até a próxima seus Nerds… hahaha